图谱近几年在互联网公司里用得非常普遍。据我所知,在 推荐领域 和 风控反作弊领域 用得非常多,最近也面试了数据挖掘岗的大大小小的互联网公司,大概 30% 的公司都问了关于图谱的一些知识。所以关于图谱的应用的需求还是非常大的,还是有必要学习下图谱的工业界一些通用的工具和套路。
图谱在应用中有一个很大的优点,它的解释能力很强,它基于一个“人以类聚,物以群分“原则,比如在社交图谱中,一个用户的所有的朋友学历水平能非常好地反映这个用户学历水平。所以在很多项目中,很多时候都是以用户近邻的特征来对该用户进行特征刻画的。
基本图的存储在大学里的《数据结构》中描述了最基本存储结构有 邻接表 和 邻接矩阵 。而对于图谱的存储,会比基本图的存储更加复杂,图谱存储细节后期再慢慢探索。好在工业界有一些非常成熟的图谱数据库的框架,目前比较流行的有 neo4j 和 orientdb 。
关于技术框架的选型, 我一般从两个层面来进行比较:1. 目前工业界普遍使用哪种,一方面身边朋友的部门在技术选型的时候用 neo4j 居多,另一方面在 数据库排行 存储图的DB中,neo4j 工业界普及率排第一,用得人多相对而言遇到各种问题,网上都可以找到答案,用得人少则会有很多隐藏着的坑;2.比较社区的活跃度,在Github活跃度 neo4j 和 orientdb ,前者活跃度 综合来看 要好于后者。综上两大点,我也选择 neo4j 进行学习。
这篇笔记主要学习下Neo4j环境的搭建,搭建包含服务端配置和客户端使用;然后再介绍下Neo4j入门级的非常常用的语法;最后进行了一个小的总结。
Neo4j环境搭建
服务端配置
服务端的选择:我一般习惯Linux系统进行后台配置,不太习惯Mac OS(兼容性会略有差别)。所以一般习惯把服务挂在Linux系统的云端,目前 云 已经渐渐成为一个基础设施了,如果只是做一些小的测试型的实验,一般最低配云服务器就可以了,价格也很便宜。我一般习惯 阿里云/腾讯云/百度云 轮流薅一遍它们的活动价,今晚薅到一台最低配的百度云 84元/年,够自己折腾一年了 ^_^。
服务端的环境依赖:对于环境依赖,没有去深究细节的依赖关系。只是按照 Github 上 Dependencies 部分挨个安装了下,Ubuntu操作系统操作细节如下:
apt update apt install maven openjdk-8-jdk apt install debhelper devscripts dos2unix dpkg make xmlstarlet curl -O http://download-keycdn.ej-technologies.com/install4j/install4j_linux_6_1_4.deb dpkg -i install4j_linux_6_1_4.debNeo4j包安装:
包的下载地址可以到官方网站下载最新版本(通常下载最新的版本): Neo4j官方下载地址 。可以在本地下载然后再Push至服务端,也可以在服务端直接执行
Curl -O https://neo4j.com/artifact.php?name=neo4j-community-4.0.0-unix.tar.gz直接下载。随后进行解压
tar -axvf neo4j-community-4.0.0-unix.tar.gz修改配置 ./conf/neo4j.conf 中的配置,下面记录下我的 最小修改配置 :
# 修改54行,去掉行前#,可以通过Web方式远程访问neo4j数据库 dbms.connectors.default_listen_address=0.0.0.0 # 修改72~83行,将 Blot/HTTP(S) 这些协议端口都打开,方便Web方式访问,端口不与其它服务端口冲突即可 # 。HTTPS 端口支持不了,把 HTTPS 设为false ,不然访问不了Web。 # Bolt connector dbms.connector.bolt.enabled=true #dbms.connector.bolt.tls_level=DISABLED dbms.connector.bolt.listen_address=:7687 # HTTP Connector. There can be zero or one HTTP connectors. dbms.connector.http.enabled=true dbms.connector.http.listen_address=:7474 # HTTPS Connector. There can be zero or one HTTPS connectors. dbms.connector.https.enabled=false dbms.connector.https.listen_address=:7473 # 修改231行,去掉行前#,设置Neo4j可读可写 dbms.read_only=false进入bin目录 启动Neo4j:
./bin/neo4j start; 停止Neo4j:./bin/neo4j stop;查看Neo4j状态:./bin/neo4j status
客户端访问
客户端访问 http://服务器ip地址:7474/browser/ 。大家可以访问我的进行测试学习:http://106.13.34.4:7474/browser/ ,如果你没有配置成功密码可以通过邮件向我索取(第一次访问帐号为 neo4j ,密码 neo4j ,首次会提示修改初始密码)。登陆后的初始页如下图如示:
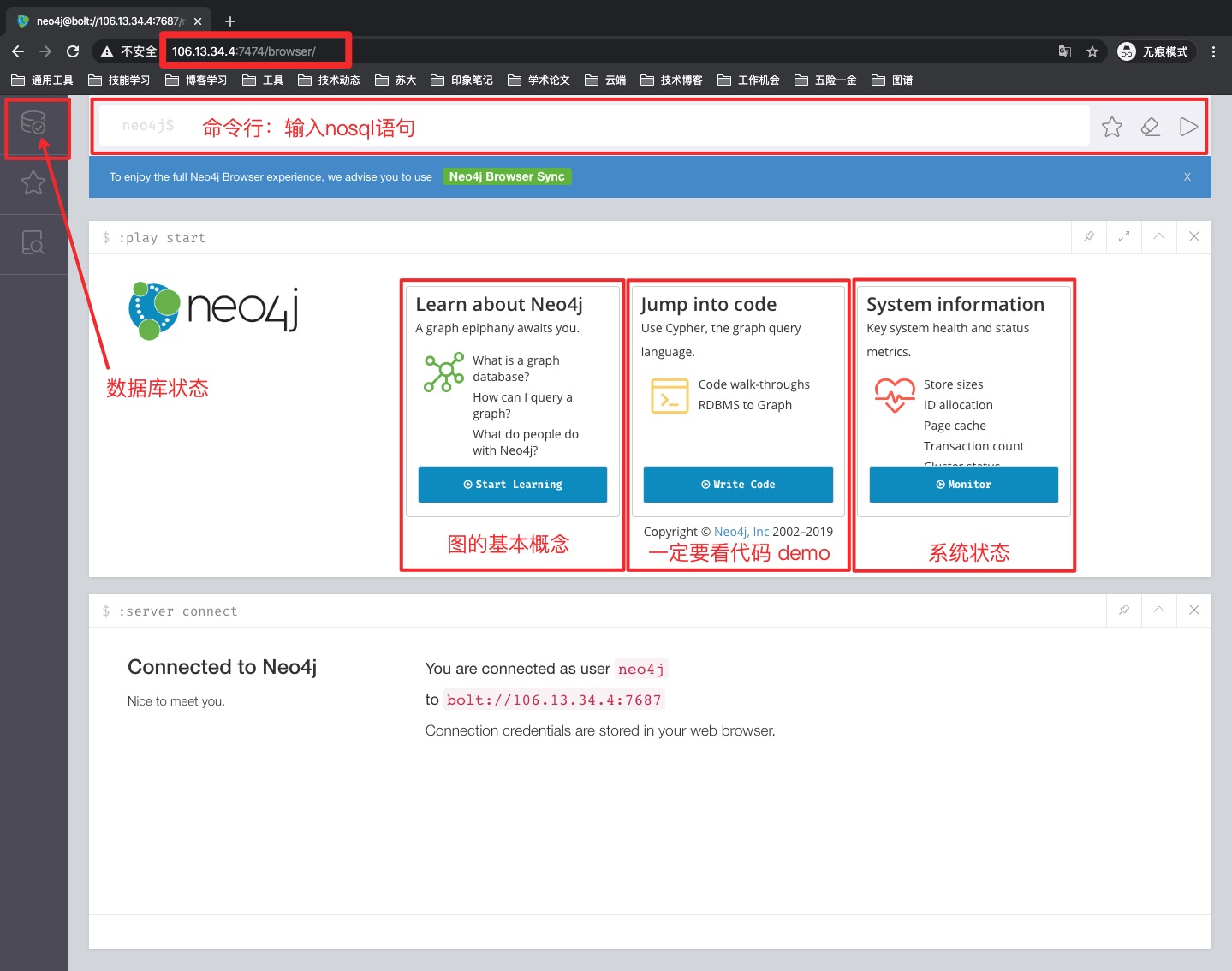
初始进入客户端Web界面时,如上图所示。
最上方条型框为命令行输入框,可以输入nosql语法的查询语句,也可以输入命令,执行查询语句或命令会出现新的子页面。这个一定要多操作、多实践。
上方的子页面:介绍了neo4j的基本使用方式。包含:1.图的基本概念(顶点的值和属性,边的值和属性);2.代码快速入门的Demo;3.查看系统状态。建议第1个图的基本概念要过一遍,第2个代码Demo 一定要亲自动手实践下,第3个是查看系统状态(监控我这边显示基本全部是 - )。
下方的子页面:显示连接的帐号为neo4j;服务端内部使用的协议为bolt协议,它是基于TCP的自定义的协议,相比HTTP来说,性能更好。
Neo4j入门语法
Neo4j属于nosql语法,和传统的sql语法差别还是挺大的。我一开始看到这种语法非常不适应,大概花了3~4天左右的时间才基本熟悉这种语法体系。这里记录下在学习demo过程中最基本的语法,后续还有待进一步学习:
Create语法
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
CREATE (Carrie:Person {name:'Carrie-Anne Moss', born:1967})
CREATE (Keanu)-[KC_Relationship:FOLLOWS {time:'20120102'}]->(Carrie)
创建节点:第1~2行,节点创建一般用小括号()来表示;Keanu 为节点的别名;Person 为节点的label名;花括号{}内为节点的属性,冒号左边为属性名,右边为属性值。
创建关系: 第4行,关系一般用中括号[]来表示,[]两侧由一对 - 分别连接两个顶点(关系的出入度通过箭头来标记);KC_Relationship 为关系的别名;FOLLOWS 为关系的label名;花括号{}内为关系的属性。
LOAD CSV WITH HEADERS FROM "http://data.neo4j.com/northwind/categories.csv" AS row
CREATE (n:Category)
SET n = row
导入节点文件: 以上是从网上csv文件导入顶点(也可以从本地路径文件进行导入);n 为节点的别名,并通过 SET 命令将 文件行数据 赋值给每个节点。对于边的构建一般会结合 MATCH 或 WHERE 命令进行 条件或路径匹配 构建。
Match语法
MATCH 命令非常的强大,可以结合 路径的匹配模式 或者 WHERE 进行条件查找,但这里只介绍下最常用的三个 MATCH 语法功能,其余的后续再不断学习(Neo4j MATCH语法 官方教程)。
查找某个节点: MATCH (Keanus {name: "Keanu Reeves"}) RETURN Keanus
显示所有节点: MATCH (n) RETURN n
删除所有节点: MATCH (n) DETACH DELETE n
总结
这篇笔记主要记录了Neo4j环境搭建,包含两个部分:云服务端的配置,Web客户端的使用;然后介绍了Neo4j最基本的入门语法:Create语法 和 Match语法。对于Neo4j的语法学习还有很长的路要走,所以我买了本《Neo4j权威指南》后续继续学习。
参考文献
- Linux环境下的Neo4j安装
- Neo4j Github 链接
- Neo4j Web客户端 Demo 教程